
- 拳交 國產 曼城出售锋线杀手,纽卡6000万追三狮国脚遭拒!
- 曼城出售锋线杀手拳交 國產,纽卡6000万追三狮国脚遭拒! 转会1+1:曼城准备卖掉9500万时尚,纽卡斯尔6千万求购三狮军团国脚,但被闭幕了。 成人伦理片 曼...

机器之心报谈耳光 调教
机器之心编订部
东谈主工神经网络、深度学习模范和反向传播算法组成了当代机器学习和东谈主工智能的基础。但现存模范频频是一个阶段更新网络权重,另一个阶段在使用或评估网络时权重保捏不变。这与好多需要捏续学习的应用标准变成显着对比。
最近,一篇发表在《nature》杂志上的盘考论文《Loss of plasticity in deep continual learning》解说:标准的深度学习模范在捏续学习环境中会冉冉失去可塑性(plasticity),直到它们的学习后果不比浅层网络好。

论文地址:https://www.nature.com/articles/s41586-024-07711-7
值得防护的是,东谈主工智能前驱、强化学习教父、DeepMind 了得盘考科学家,阿尔伯塔大学诡计机科学教化 Richard S. Sutton 是这篇论文的作家之一。
通俗来说,该盘考使用经典的 ImageNet 数据集、神经网络和学习算法的各式变体来展示可塑性的丧失。只消通过握住向网络注入万般性的算法才能无穷期地保管可塑性。基于这种念念路,该盘考还提倡了「捏续反向传播算法」,这是反向传播的一种变体,其中一小部分较少使用的单位被捏续就地地从头动手化。试验完毕标明,基于梯度下跌的模范是不够的,捏续的深度学习需要就地的、非梯度的因素来保捏可变性和可塑性。
ImageNet 数据库包含数百万张用名词(类别)绚烂的图像,举例动物类型和闲居物品。典型的 ImageNet 任务是猜想给定图像的标签。
为了使 ImageNet 相宜捏续学习,同期最大放置地减少扫数其他变化,该盘考通过成对的类构建了一系列二元分类任务。举例,第一个任务可能是鉴识猫和房屋,第二个任务可能是鉴识泊车标志和校车。诈欺数据集中的 1000 个类,该盘考好像以这种情势变成 50 万个二元分类任务。
对于每个任务,该盘考最初在两个类的图像子集上素养深度学习网络,然后在这些类的单独测试集上测量其性能。在一个任务上素养和测试后,下一个任务从一双不同的类动手。盘考团队将此问题称为「捏续 ImageNet(Continual ImageNet)」。在捏续 ImageNet 中,任务的难度跟着期间的推移保捏不变。性能下跌意味着网络正在失去学习能力,这是可塑性丧失的平直弘扬。
该盘考将各式标准深度学习网络应用于 Continual ImageNet,并测试了好多学习算法和参数建造。为了评估网络在职务中的性能,该盘考测量了正确分类测试图像的百分比。
该盘考发现:对于经过致密补救的网络,性能频频最初莳植,然后大幅下跌,最终接近或低于线性基线。当性能动手下跌时,网络架构、算法参数和优化器的具体继承会产生影响,但多种继承都会导致性能严重下跌。标准深度学习模范在后续任务中无法比线性网络更好地学习,这平直解说这些模范在捏续学习问题中后果欠安。

令东谈主讶异的是耳光 调教,Adam、Dropout 和归一化等流行模范骨子上增多了可塑性的亏本;而 L2 正则化在许厚情况下减少了可塑性的亏本。

盘考团队发现:显式保捏网络权重较小的算法频繁好像保捏可塑性,以致在好多任务中好像莳植性能。
该盘考基于上述发现,提倡了反向传播算法的一种变体 —— 捏续反向传播,该算法向网络注入可变性并保捏其某些权重较小。
模范
捏续反向传播
捏续反向传播算法将继承性地对汇集中低效的单位进行动手化惩处。盘考团队界说了名为「孝敬遵守」的值来预计每个单位的紧迫性。如若神经汇集中某个荫藏单位对它所连系的卑鄙单位的影响很小,那么它的作用就可能被汇集中其他更有影响力的荫藏单位粉饰。

当一个荫藏单位被从头动手化时,它的输出的权重将被迫手化为零。这样作念是为了新添加的荫藏单位不会影响模子仍是学到的功能。然则这样也容易导致新的荫藏单位很快被从头动手化。
为了持重这种情况,盘考团队建造了「熟悉阈值」,在 m 次更新前,即使新的荫藏单位的遵守是零,也不会被从头动手化。当更新次数逾越 m 后,每一步「熟悉单位」的一部分 ρ(称为替换率),在每一层都会被从头动手化。替换率 ρ 频繁建造为一个相称小的值,这意味着在数百次更新后只替换一个单位。举例,在 CIFAR-100 中,盘考团队将替换率建造为 10 的负五次方,每一步,不祥 0.00512 个单位被替换。这至极于不祥每 200 次更新替换一次。
最终的算法皆集了传统的反向传播和继承性从头动手化两种模范,以捏续地从动手散布中引入就地单位。每次更新时,捏续反向传播将实行梯度下跌并继承性地从头动手化。
前馈神经网络的捏续反向传播如算法1所示。惩处小批量数据时,不错遴选一种更经济的模范:通过对小批量数据上的即时孝敬遵守取平均值,美国艳星而不是保捏一个运行平均值来省俭诡计量。


在 ImageNet 上的应用
盘考使用了包含 1000 个类别的 ImageNet 数据库,每个类别有 700 张图片,分为 600 张素养图像和 100 张测试图像。在二元分类任务中,网络最初在 1200 张素养图像上素养,然后在 200 张测试图像上评估分类准确度。
扫数在捏续 ImageNet 上使用的算法都秉承了具有三个卷积加最大池化(convolutional-plus-max-pooling)层和三个全连系层的卷积网络。最终层有两个单位,对应两个类别。在职务变更时,这些单位的输入权重会重置为零。这种作念法在深度捏续学习中是标准作念法,尽管它为学习系统提供了对于任务变化期间的特权信息。
线性网络的性能在捏续 ImageNet 上不会下跌,因为它在每个任务动手时都会重置。通过在数千个任务上取均值,得到线性网络性能的低方差算计值,行动基线。
网络使用带有动量的 SGD 在交叉熵亏本上进行素养,动量参数设为 0.9。盘考者测试了不同的步长参数,但为了了了起见,只展示了 0.01、0.001 和 0.0001 的步长性能。
该盘考还通过网格搜索细目了 L2 正则化、减轻和扰动以及捏续反向传播算法的超参数,以在 5000 个任务上获取最高的平中分类准确度。L2 正则化和减轻扰动的超参数包括步长、权重衰减和噪声方差,捏续反向传播的超参数包括步长和替换率,熟悉度阈值设为 100。
盘考者对扫数超参数皆集进行了 10 次沉着运行,然后对弘扬最好的超参数皆集进行了稀薄的 20 次运行,整个 30 次。

CIFAR-100 的类别增量学习
伊伊系列在 CIFAR-100 的类别增量学习中,动手时,模子不错识别 5 种类型的图片,跟着素养期间越来越长,模子能识别的图片种类越来越多,比如能同期学习 100 种类别的图片。在这个进程中,系统将通过测试磨真金不怕火我方的学习后果。数据集由 100 个类别组成,每个类别有 600 张图像,其中 450 张用于创建素养集,50 张用于考据集,100 张用于测试集。
每次增多学习的类别后,网络被素养 200 个周期,整个增多 20 次,共素养 4000 个周期。盘考团队在前 60 个周期中将学习率建造为 0.1,接下来的 60 个周期为 0.02,尔后的 30 个周期为 0.004,终末的 40 个周期为 0.0008。在每次增多的 200 个周期中,盘考团队选出了在考据集上准确度最高的网络。为了持重过拟合,在每轮素养中,新网络的权重将被重置为上一轮准确度最高网络的权重。
他们继承了 18 层的 ResNet 作念试验。在将输入图像呈现给网络之前,该盘考进行了几个模范的数据预惩处。最初,将每张图像中扫数像素的值从头缩放到 0 和 1 之间。然后,每个通谈中的每个像素值通过该通谈像素值的平均值和标准差分别进行中心化和从头缩放。终末,在将图像输入给网络之前,该盘考对每张图像应用了三种就地数据补救:以 0.5 的概率就地水平翻转图像,通过在每边填充 4 个像素然后就地剪辑到原始大小来就地剪辑图像,以及在 0-15° 之间就地旋转图像。预惩处的前两步应用于素养集、考据集和测试集,但就地补救仅应用于素养集中的图像。

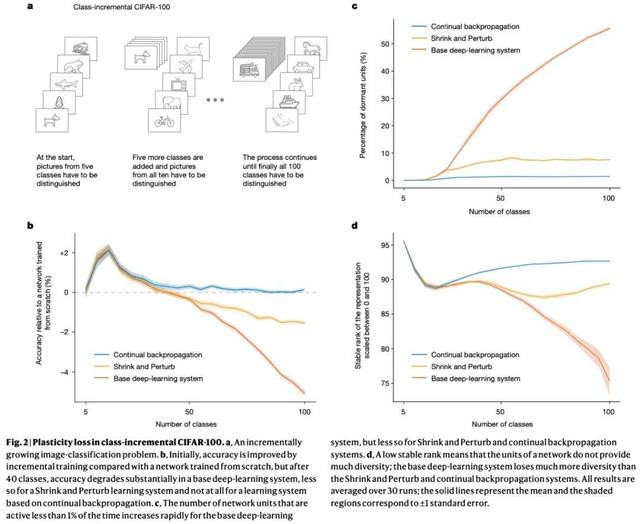
行动参考,该盘考还达成了一个具有与基础系统疏导超参数的网络,但在每次增量的动手时都会从头动手化。图 2b 涌现了每个算法相对于从头动手化网络的性能弘扬。
捏续反向传播在一起的 100 个类别中的最终准确率为 76.13%耳光 调教,而扩张数据图 1b 展示了在熟悉度阈值为 1000 时,捏续反向传播在不同替换率下的性能弘扬。